
AGI Existential Risk Persists Despite Controls That Buy Time

This post is early this week to meet a deadline for an essay contest.
Given advances in artificial intelligence over the past few years, it seems likely that artificial general intelligence (AGI) could emerge by 2070. And the rapid advance of AI capabilities raises urgent questions about current and future risks of this technology.
Put simply, whenever capabilities outpace controls, risk increases. Innovation throughout human history has featured this dynamic, and we are still here. But with AI, a different approach will become necessary as capabilities advance toward human-level AGI: controls will need to catch up to, keep pace with, and eventually outpace capabilities.
A few rudimentary graphs can illustrate why. If capabilities improve faster than controls, risk also increases, likely at a greater-than-linear rate1. And in a so-called fast-takeoff AI scenario, where AGI exceeds human intelligence and begins improving itself at rapid speed, the curves are likely to diverge sharply, leaving a large and ever-widening gap between sophistication of controls and capabilities.

Those curves are likely not compatible with thriving human societies. A growing gap between controls and capabilities would represent increasing potential for existential disasters or catastrophes over time.
That is why controls must catch up to, then keep pace with, and eventually exceed capabilities. Yes, that will mean periodic slowdowns and eventually a stopping point. It will not mean all risk is eliminated; instead, it will mean that controls are commensurate with the level of risk and sufficient to reduce risk to an acceptable level.
If capabilities and controls evolve at a similar pace, that might look something like this (a more traditional scenario on the left, and a better scenario on the right):
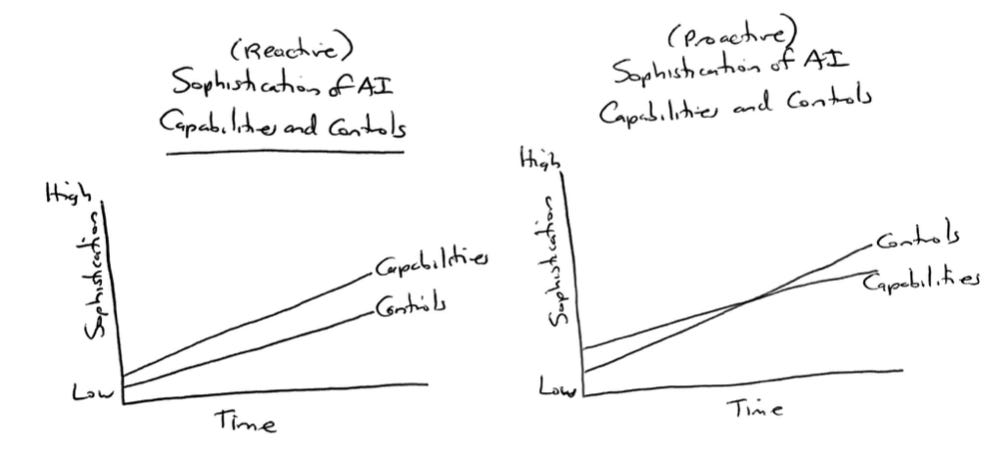
The scenario on the right buys time, manages risk, and reduces the likelihood of any sudden and un-manageable takeoff in capabilities. It opens the door for humans to benefit from AI capabilities while keeping risks reasonably in check.
But such an approach would likely work only as long as humans (and the controls they design) are smarter than AI. Almost by definition, AGI that reaches or exceeds human-level intelligence would learn to outmaneuver human controls and increase its own capabilities faster than human controls could catch up (bringing us back to that first graph with the exponential capabilities curve far outpacing controls).
Therefore, if we approach (note: I did not say reach, because reaching that point would be too late) a point where risk can no longer be reduced to an acceptable level, the only adequate control will be to stop.
One possible way to think about this would be to visualize human-level AGI as a threshold and then aim to leave a margin of safety between controls and capabilities and that perhaps-irreversible threshold. The margin should be ample to allow for uncertainty. Visually, it might look something like this2:

Admittedly, this seems like a tall order, and threading the needle will be tricky. Yet, the world has (imperfectly but acceptably) managed the potentially existential risk of nuclear weapons for about 80 years via stringent risk controls and international regulatory coordination through the International Atomic Energy Agency (IAEA). With AI, another factor that’s not present with nuclear weapons is the need to align AI systems with human interests and priorities.
We’ll cover each of these three areas—operational risk controls, alignment, and regulation—in turn, and then consider how the combination of these balancing feedback loops may buy time and ultimately set boundaries to prevent humanity from crossing a possibly-irreversible threshold beyond which AGI could spiral out of our control.
Operational Risk Controls - A Brief Overview
As I wrote in my essay Possible Paths for AI Regulation3, companies and organizations developing or using AI need to implement controls commensurate with the risk posed by the technology. That doesn’t mean—and shouldn’t mean— implementing layers of process or paperwork without reducing risk. Instead, some characteristics of effective controls are:
They are supported rather than undermined at the highest levels of the organization and are well-communicated throughout the organization.
They are well-placed at high-leverage points within processes and systems.
They target the root causes of risk and prioritize prevention when possible.
They cost less than the risks they protect against and avoid unnecessary overhead.
They allow sufficient flexibility for buy-in and strategic implementation across different departments’ workflows while minimizing exceptions and workarounds.
They are forward-looking, with consideration of how processes and systems are evolving and how the controls might apply to their anticipated future states.
Their second-order effects are manageable and do not undermine the intent of the controls (e.g., by driving activity “underground” without actually reducing risk)
More specifically, some key principles for operational risk controls include:
Defense in depth: Failure of one control should never lead to catastrophic failure of the entire control system. Single points of failure are out; redundancy and diversity of controls are in. Redundancy of controls means multiple controls are used to address the same risk. Diversity of controls means different types of controls are used to address the same risk. The diversity of controls can be broad, and the redundancy of controls can be deep, depending on the risk posed by a system.
However, this doesn’t mean controls should be implemented haphazardly, stacked all together in one place, or at every point in a process or system. Instead, controls should be implemented at high-leverage points in processes and systems. For example, when dealing with high-volume data, if a set of chokepoints can be identified through which all or most data must eventually flow, those are optimal points for control application.
Prioritizing controls over expediency: As a general principle, activating a control should be easier than overriding it.
Prioritizing preventive controls: Because AI is faster than humans, preventive controls take on more importance than detective or corrective controls. Key examples of preventive controls include alignment approaches (discussed later), separation of duties, and change management.
Separation of duties: No single person should be able to take drastic action to increase or alter AI’s capabilities. The more drastic the escalation of capabilities, the more stakeholders and sign-offs should be required. Lively debate among stakeholders should be encouraged, not squashed, since the safety increase from additional sign-offs could be compromised if stakeholders feel they can’t speak up without negative consequences.
Similarly, no single person should be able to override an AI rule or a control. If the rule or control is critical enough, high-level approval should be required to override it. In the most critical situations, no single person should know about all the controls or have the power to override all the controls they know about, so even if an AI convinces humans to override controls, not all controls may be overridden.
Change management: No matter how good or trusted a developer is, they can always benefit from code review and a formal change management process. No developer should be able to unilaterally test their own code with no additional review or push their own code into production outside of a formal change management process.
Detective and corrective controls: True AGI would likely be able to outpace or undermine detective and corrective controls. But in the years before AGI’s creation, there is still time to identify when things go wrong and then correct the deficiencies that allowed incidents to occur.
For example, automated detective controls might identify a massive and unexpected volume of requests flowing from an AI system and shut it down until humans can review the traffic and determine what happened.
Manual kill switches can serve as corrective controls activated by humans in response to AI malfunction or misaligned action, although designers of kill switches need to balance speed (is there time to hit the switch and stop AI?) with assessment of second-order effects (will doing this cause an even bigger problem?).
Immutable logging can help detect anomalies and malfunctions, such as when patterns of use or operation shift in unexpected ways (e.g., an AI logs into a system at an unusual time or tries to access a new resource, or a developer deletes records to cover their tracks).
Near-miss reporting and remediation can help AI developers and users address root causes and avoid future errors before risk fully manifests. Judiciously sharing risks, near-misses, and mitigation strategies across companies and organizations, possibly through an independent information-sharing organization, without naming names, placing blame, or identifying specific firms’ weaknesses, can strengthen the resilience of the entire ecosystem.
Overall, controls are not keeping pace with AI capabilities right now. It’s not a catastrophe right now, either, because current AI systems don’t pose existential risk. But as AI capabilities advance further and existential risks move into the realm of the plausible, controls will need to catch up, start keeping pace with, and ultimately outpace capabilities.
AI Alignment - An Important Piece of the Puzzle
One aspect of AI risk control that bears special mention is alignment of AI systems with human interests and goals. Think of Isaac Asimov’s canonical Three Laws of Robotics: essentially, prioritize human well-being and don’t injure humans; obey human orders unless those orders would injure humans; and protect oneself unless doing so would conflict with human orders or injure humans.
In principle, it sounds good. But in practice, there are lots of ways this type of guidance can go wrong. Think of those fables where hapless humans find genies in a bottle and make sub-optimal wishes. Precisely defining our wishes is extremely hard.
But just because this problem is hard—and perhaps impossible to make bulletproof—doesn’t mean it can’t be a component of AI risk control. Avoiding reliance on a single control is redundancy and diversity of controls in action! And alongside other AI risk controls, alignment can play an important role. The current situation of rapidly advancing AI capabilities without commensurate breakthroughs in alignment increases risk.
Some under-explored avenues for alignment research may prove fruitful. As just one example, on the question of corrigibility (developing AI systems that are amenable to shutdowns and other interventions), it might be possible to explore approaches based on biological systems principles such as homeostasis and apoptosis (which is essentially corrigibility at the cellular level in biological organisms, since it destroys components of the organism to benefit the whole). What if corrigibility can be built into AI systems not at the whole-system level but at lower levels (layer, weight/parameter, etc.), where whole-system incentives are less likely to oppose or may even favor shutdown of components that diverge from homeostasis (the pre-trained state)?
In addition, on the broader question of alignment, it seems possible that AIs given goals that operate as balancing feedback loops (such as homeostasis aka “maintain the pre-trained state”) could prove easier to align than AIs given goals that operate as reinforcing feedback loops (e.g., “win this game”). Alignment research has explored goal definition before, but a system dynamics lens may offer fresh insights.
Overall, much research remains to be done on alignment, but it’s an important piece of the puzzle.
Good Regulation - Hard But Feasible
Like effective controls, there are several characteristics of effective regulation. As I wrote in my essay Emerging Risks and Smart Regulation4, effective regulation:
Is targeted.
Engages the governed, listening to their concerns and gaining their trust as a governed party to ensure buy-in at a strategic level instead of tactical compliance in a check-the-box exercise.
Is not make-work and is reasonably time-efficient, allowing sufficient flexibility in implementation for different types of businesses and organizations.
Ideally makes required something industry participants mostly wanted to do anyway but couldn’t since doing so would have put them at a perceived or actual market disadvantage. In essence, regulation in this situation is a key for overcoming a prisoner’s dilemma.
Helps ensure safety for stakeholders that have insufficient leverage to negotiate with more powerful stakeholders on their own (consumer protection regulation is an example).
Is forward-looking, with consideration of how processes and systems are evolving and how the regulation might apply to their anticipated future states.
Costs businesses and societies less than the risk it protects against.
Has second-order effects that are manageable and do not undermine the intent of the regulation (e.g., by driving activity outside of the regulatory jurisdiction en masse without actually reducing risk in the system as a whole).
Although good regulation is hard, it’s not impossible. One example of a good regulation (in my opinion) is an SEC rule called 15c3-5. Prior to this regulation, broker-dealers could give clients their market participant identifier (MPID) and let the clients send orders directly to the markets themselves. This posed potentially significant risks for markets and for the broker-dealer if a client (e.g., a hedge fund) did not have sufficient controls to catch erroneous orders sent by their trading algorithms. An order might be too large (a fat-finger order), or an algorithm might send millions of orders in quick succession, causing market instability and risk exposure.
After the regulation, orders had to flow through a layer of broker-dealer risk controls. Broker-dealers have sufficient money and resources to implement controls in a way that their small clients might not. (Broker-dealers also can develop metrics around near-misses, events, incidents, trends, etc.)
This example might have applicability for AI regulations and metrics, not least because training clusters might serve as bottleneck points where controls could be applied. And take a look at what the SEC wrote about industry feedback after this regulation was proposed:
“Nearly all of the commenters supported the overarching goal of the proposed rulemaking—to assure that broker-dealers with market access have effective controls and procedures reasonably designed to manage the financial, regulatory, and other risks of that activity.”5
Of course, “… several commenters recommended that the proposal be amended or clarified in certain respects.”6 Every organization also considers its self-interest and has incentives to sway regulation in its own favor. But the broad, high-level agreement with the proposed rule indicated it was on the right track—and the regulators ultimately implemented it “substantially as proposed.”
I’ll delve more into this and other regulations and what makes them (in my view) effective in a future post, but suffice to say that effective regulation is hard but not impossible. (It’s almost certainly easier than getting perfectly aligned AI, especially across an industry.)
Summing It Up and Shifting the Risk Curve
So, given the need for strong operational risk controls, better AI alignment approaches, and effective regulation, what is the chance that losing control of AGI will bring about existential catastrophe for humanity?
Over the long haul, if risk controls, alignment, and regulation work in tandem, it’s highly possible that they will buy time to catch up to, keep pace with, and eventually exceed capabilities innovation. Instead of a capabilities-controls relationship like the one on the left, we could get the one on the right:

The curve on the right we can deal with; we can evolve alongside it and adjust to oscillations around it. The capabilities curve on the left is probably too steep for us to handle. So, the combination of controls, alignment, and regulation could help us enjoy benefits of AI (e.g., new medicines, innovative energy solutions) while reducing7 the risks.
But over the long haul, the risk of existential catastrophe still seems high if true AGI that exceeds human-level intelligence is developed. Even effective risk controls and regulations extend only to the boundaries of human intelligence. Beyond those boundaries, getting outmaneuvered eventually becomes almost certain, just as humans outmaneuver ants when we set out sugary baits that the ants happily tote back to their nest.
One of the best things controls, alignment approaches, and regulations can do for us, therefore, is to help us identify when we approach (remember: not reach, since reaching that point would be too late) a point where risk can no longer be reduced to an acceptable level.
This raises a thorny question: what is the acceptable level of risk? Whether humans can agree on a reasonable answer, and can make the choice to stop when risk exceeds that level, will determine the outcome of our foray into artificial intelligence. The stakes are high, yet we have successfully threaded this needle before with nuclear weapons. (After all, we don’t have individual nuclear reactors on top of each home’s roof, and we don’t sell nuclear chemistry kits for kids. We stopped before we reached that point!) Whether we can thread it now with an even more complex technology, ensuring controls catch up to, keep pace with, and eventually outpace capabilities—and making the decision to stop if or when that’s no longer possible—will determine our future.
Every capabilities increase has second-, third-, and nth-order effects that increase system complexity.
Note that controls that reach the level of AGI also would be dangerous, so if controls eventually outpace capabilities, then the margin of safety would be the difference between sophistication of controls and the likely AGI threshold.
Losi, Stephanie. “Possible Paths for AI Regulation.” October 27, 2022.
Losi, Stephanie. “Emerging Risks and Smart Regulation.” October 20, 2022.
“Risk Management Controls for Brokers or Dealers with Market Access”, page 4, https://www.sec.gov/rules/final/2010/34-63241.pdf
“Risk Management Controls for Brokers or Dealers with Market Access”, page 4, https://www.sec.gov/rules/final/2010/34-63241.pdf
As any information security specialist will tell you, it’s impossible to eliminate all risk, and there’s no such thing as perfection.
AGI is an interesting thing to worry about. This was a great essay. Good luck in your essay contest.